Nowa kategoria w Lighthouse: Przeglądanie agentowe (i jak brylka.net robi 3/3)
Lighthouse przez lata miał cztery kategorie: Wydajność, Ułatwienia dostępu, Sprawdzone metody i SEO. Od niedawna doszła piąta – Przeglądanie agentowe (Agentic browsing). To znak czasów: strona ma być czytelna nie tylko dla ludzi i crawlerów wyszukiwarek, ale też dla agentów AI, które coraz częściej klikają w sieci za nas. Postanowiłem sprawdzić, jak wypada brylka.net – i wyszło komplet:
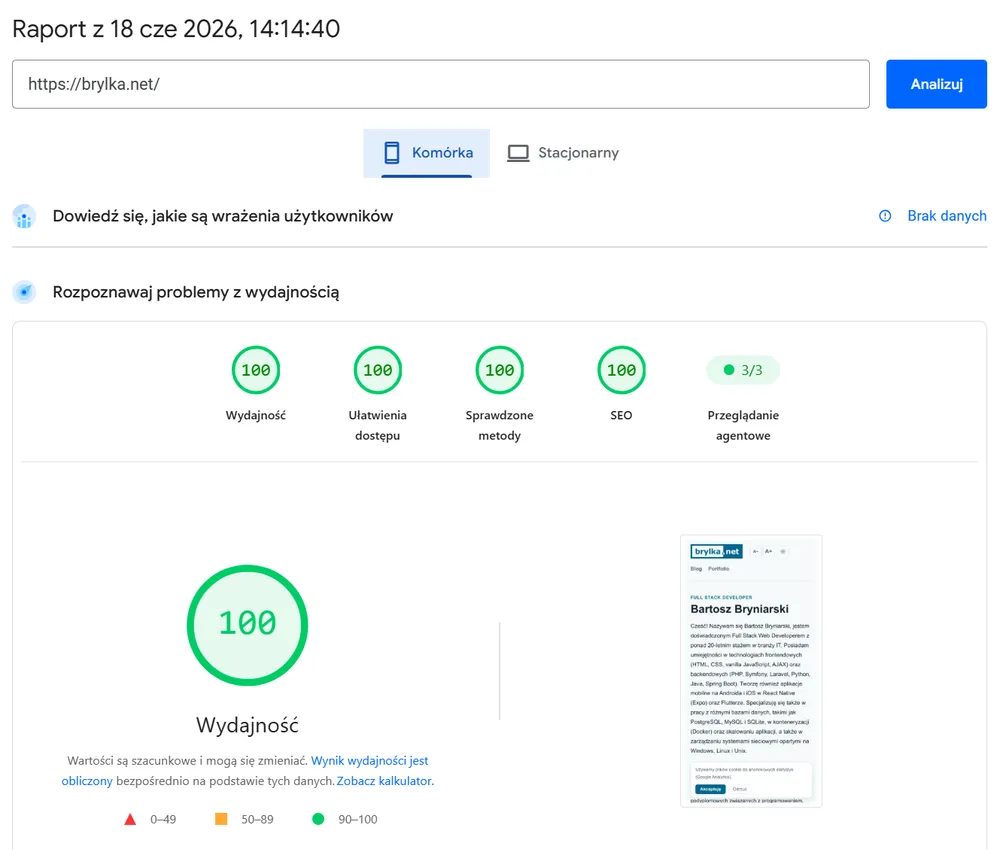
100 / 100 / 100 / 100 i 3/3 w przeglądaniu agentowym. W tym wpisie rozkładam tę nową kategorię na czynniki pierwsze: co sprawdza, dlaczego dobre fundamenty wystarczają do 3/3 i czym jest tajemnicze WebMCP, które na razie widnieje jako „nie dotyczy”.
Czym jest „Przeglądanie agentowe”
Klasyczne SEO pyta: czy robot wyszukiwarki zaindeksuje treść? Przeglądanie agentowe pyta o coś więcej: czy agent AI potrafi tę stronę zrozumieć i obsłużyć – odczytać strukturę, znaleźć elementy, kliknąć właściwy przycisk, wypełnić formularz. To inny scenariusz niż indeksacja: agent realnie działa na stronie w sesji przeglądarki użytkownika.
Dwie różnice względem pozostałych kategorii:
- Nie ma wyniku 0–100. Zamiast tego Lighthouse pokazuje ułamek zaliczonych kontroli (u mnie 3/3) plus listę pass/fail.
- To kategoria w budowie. Lighthouse sam zaznacza, że jest „nadal w trakcie opracowywania i może ulec zmianie” – więc zestaw audytów będzie się jeszcze ruszał.
Co dokładnie sprawdza
Po rozwinięciu kategorii widać konkrety:
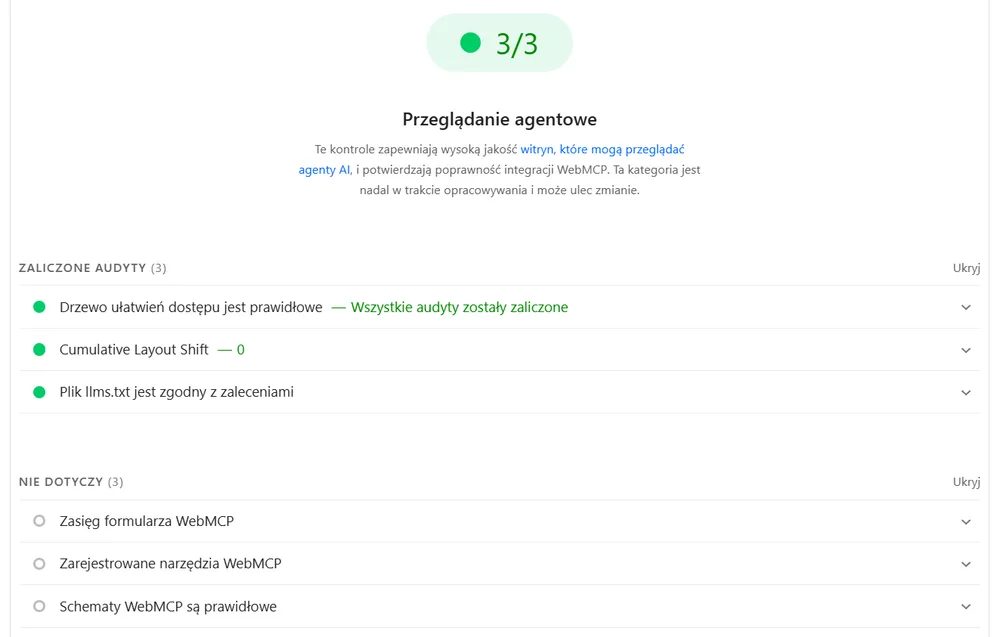
Trzy audyty zaliczone i trzy oznaczone jako „nie dotyczy”:
- Drzewo dostępności jest prawidłowe – agenci nie „widzą” strony jak człowiek; ich głównym modelem danych jest drzewo dostępności. Lighthouse wybiera podzbiór audytów a11y krytycznych dla maszyny: każdy interaktywny element ma programową nazwę, role i relacje rodzic–dziecko są poprawne, a treść interaktywna nie jest ukryta przed drzewem.
- Cumulative Layout Shift = 0 – skoro agent klika po pozycji elementów, stabilność układu jest kluczowa. Element, który „ucieka” po renderowaniu, to dla agenta to samo co dla człowieka: chybione kliknięcie.
- Plik
llms.txtjest zgodny z zaleceniami – Lighthouse sprawdza, czy w korzeniu domeny jest/llms.txt: zwięzła, maszynowa mapa serwisu dla modeli językowych. - WebMCP (3× „nie dotyczy”) – zasięg formularza WebMCP, zarejestrowane narzędzia WebMCP i poprawność schematów WebMCP. O tym za chwilę.
Jak brylka.net zdobywa 3/3 bez specjalnej roboty
Najciekawsze jest to, że pod tę kategorię nie zrobiłem nic dedykowanego. 3/3 wyszło jako efekt uboczny rzeczy, które i tak warto mieć:
- Drzewo dostępności – to dywidenda z dbania o A11y: prawdziwe
<button>-y zamiast klikalnychdiv-ów, etykietyaria-label, sensowne nagłówki,altprzy obrazach. Robione dla ludzi, działa też dla agentów. - CLS 0 – statyczny Astro, brak skaczących reklam, obrazy z jawnymi
width/height. Nic nie przeskakuje. llms.txt– mam go generowanego automatycznie z treści, więc audyt przechodzi sam z siebie.
To ładnie domyka myśl z wpisu Platforma webowa dogoniła biblioteki: dobre, czyste fundamenty (semantyka, stabilność, dane maszynowe) są jednocześnie gotowością pod agenty AI. GEO i agentic browsing to nie osobna robota – to ta sama higiena.
WebMCP – czyli to „nie dotyczy”
Trzy audyty WebMCP są u mnie nieaktywne, bo… nie mam WebMCP. I to jest w porządku – wyjaśnijmy, co to znaczy.
WebMCP (Web Model Context Protocol) to powstający standard W3C (rozwijany m.in. przez Google i Microsoft), który pozwala stronie wystawić agentowi gotowe „narzędzia” zamiast zmuszać go do zgadywania po zrzucie ekranu, gdzie kliknąć. Strona przy ładowaniu rejestruje narzędzia w przeglądarce:
// API jest eksperymentalne (Chrome 146, za flagą) - przykład poglądowy
navigator.modelContext?.registerTool({
name: "search_posts",
description: "Wyszukuje wpisy na blogu po słowie kluczowym",
inputSchema: {
type: "object",
properties: { query: { type: "string" } },
required: ["query"],
},
async execute({ query }) {
// zwróć agentowi listę pasujących wpisów (tytuł + URL)
return { results: await findPosts(query) };
},
});Zamiast „agent robi screenshot → model zgaduje współrzędne → klika”, strona mówi wprost: „oto co potrafię, oto parametry, oto jak to wywołać”. To znacznie pewniejsze niż klikanie na ślepo.
Dlaczego więc u mnie „nie dotyczy”? Bo blog to treść do czytania, a nie aplikacja z akcjami do wystawienia. Nie mam formularzy ani operacji, które agent miałby wykonywać – jest tekst, a od mapowania treści jest llms.txt. Audyty WebMCP są więc słusznie nieaktywne.
I rzecz najważniejsza: „nie dotyczy” nie obniża wyniku. Ułamek 3/3 liczy audyty mające zastosowanie – a te wszystkie przechodzą. To nie jest „czerwone do naprawienia”, tylko „nie dotyczy tej strony”. WebMCP jest dodatkowo eksperymentalne (Chrome 146 to dopiero Early Preview za flagą), więc bez konkretnego powodu nie wdrażałbym go produkcyjnie.
Z czystej ciekawości sprawdziłem jednak później, czy taki statyczny blog w ogóle da radę wystawić WebMCP – bez backendu – i dorzuciłem narzędzie wyszukiwania wpisów wraz z frontową wyszukiwarką. Jak to zrobić na czystym statyku i co na to Lighthouse, opisuję w osobnym wpisie: Jak dodałem WebMCP i frontową wyszukiwarkę – blog gotowy na agenty AI.
Podsumowanie
Piąta kategoria Lighthouse to sygnał, w którą stronę idzie sieć: obok „czy człowiek i wyszukiwarka dadzą radę” dochodzi „czy poradzi sobie agent AI”. Dobra wiadomość jest taka, że jeśli robisz porządną robotę – semantyczny HTML, stabilny układ, dane maszynowe – dostajesz gotowość pod agenty gratis. brylka.net ma 3/3 nie dzięki sztuczkom pod audyt, tylko dzięki fundamentom, które i tak służą ludziom.
Po szczegóły o samej kategorii warto zajrzeć do dokumentacji Chrome o punktacji agentic browsing. A jeśli interesuje Cię, jak przygotować treść pod modele językowe, mam o tym osobny wpis: llms.txt i GEO.
