Jak dodałem WebMCP i frontową wyszukiwarkę – blog gotowy na agenty AI
W poprzednim wpisie o kategorii „Przeglądanie agentowe” zostawiłem audyty WebMCP jako „nie dotyczy” – bo blog to treść, nie aplikacja z akcjami. Ale zostało pytanie, które nie dawało mi spokoju: czy statyczny blog, bez żadnego backendu, w ogóle da radę wystawić WebMCP – i czy da się ubić pełne 6/6? Postanowiłem sprawdzić empirycznie. Spoiler: na statyku się da, a „6/6” okazało się ciekawszym tematem, niż myślałem.
Czy bez backendu się da? Tak – WebMCP żyje w przeglądarce
To była pierwsza rzecz do ustalenia. WebMCP działa po stronie klienta – w przeciwieństwie do „serwerowego” MCP, narzędzia rejestruje się w przeglądarce użytkownika, a ich kod wykonuje się lokalnie. Żadnego serwera nie potrzeba.
Jedyne, czego potrzebuje sensowne narzędzie wyszukiwania, to lista wpisów dostępna w przeglądarce. Generuję ją przy buildzie jako statyczny plik – /posts-index.json – dokładnie tak, jak rss.xml czy llms.txt:
// src/pages/posts-index.json.js – statyczny endpoint z kolekcji treści
import { getPosts } from '../lib/posts.js';
import { SITE } from '../lib/config.js';
export async function GET() {
const posts = await getPosts();
const data = posts.map((p) => ({
title: p.data.title,
url: new URL('/' + p.id, SITE).href,
description: p.data.description ?? '',
tags: p.data.tags ?? [],
}));
return new Response(JSON.stringify(data), {
headers: { 'Content-Type': 'application/json; charset=utf-8' },
});
}Filtrowanie tej listy robi się w JS, w przeglądarce. Zero compute po stronie serwera – czysty statyk na edge.
Krok 1: imperatywne narzędzie (navigator.modelContext.registerTool)
Pierwsze podejście to API imperatywne – skrypt rejestruje narzędzie przy ładowaniu strony. Całość jest feature-detected, więc dla zwykłych przeglądarek (bez WebMCP) to no-op:
if (navigator.modelContext && typeof navigator.modelContext.registerTool === "function") {
let cache = null;
const loadPosts = async () => (cache ??= await (await fetch("/posts-index.json")).json());
navigator.modelContext.registerTool({
name: "search_posts",
description: "Przeszukuje wpisy bloga po słowie kluczowym i zwraca tytuł oraz URL.",
inputSchema: {
type: "object",
properties: { query: { type: "string", description: "Słowo lub fraza" } },
required: ["query"],
},
async execute({ query }) {
const q = String(query || "").toLowerCase().trim();
const posts = await loadPosts();
const results = posts
.filter((p) => (p.title + " " + p.description + " " + (p.tags || []).join(" ")).toLowerCase().includes(q))
.slice(0, 10)
.map((p) => ({ title: p.title, url: p.url }));
return { content: [{ type: "text", text: JSON.stringify({ results }) }] };
},
});
}Agent dostaje narzędzie, które zwraca ustrukturyzowaną listę wyników – zamiast robić zrzut ekranu i zgadywać, gdzie kliknąć.
Krok 2: frontowa wyszukiwarka (realna funkcja, nie atrapa)
Skoro już mam indeks wpisów w przeglądarce, grzechem byłoby nie dać z niego pożytku ludziom. Na /blog dorzuciłem zwykłą, kliencką wyszukiwarkę – pole <input type="search"> w <form>, które filtruje widoczne karty po tytule, opisie i tagach (łącząc się z istniejącym filtrem tagów). Działa w każdej przeglądarce, bez WebMCP – to po prostu przydatny search.
Krok 3: deklaratywne WebMCP na formularzu
Tu zaczęła się prawdziwa analiza. Audyt webmcp-form-coverage w pierwszych przebiegach krzyczał: „1 form missing annotations”. Okazało się, że WebMCP ma drugie, deklaratywne API: oznaczasz <form> atrybutami toolname i tooldescription (plus toolparamdescription na polach), a przeglądarka sama generuje z formularza narzędzie i jego schemat:
<form
class="search"
role="search"
aria-label="Szukaj wpisów"
toolname="search_blog_posts"
tooldescription="Wyszukuje wpisy na blogu brylka.net po słowie kluczowym i pokazuje pasujące artykuły."
>
<input
type="search" name="q" placeholder="Szukaj wpisów…"
toolparamdescription="Słowo lub fraza do wyszukania we wpisach (tytuł, opis, tagi)"
/>
</form>To podejście jest odporniejsze niż imperatywne: nie zależy od momentu wykonania JS, bo narzędzie wynika wprost z HTML. To ono okazało się kluczem do ustabilizowania audytów.
Próba 6/6 – i co naprawdę się dzieje
Po wdrożeniu wszystkiego uruchomiłem Lighthouse na /blog (w Chrome z włączoną flagą WebMCP) wiele razy. Oto wynik:
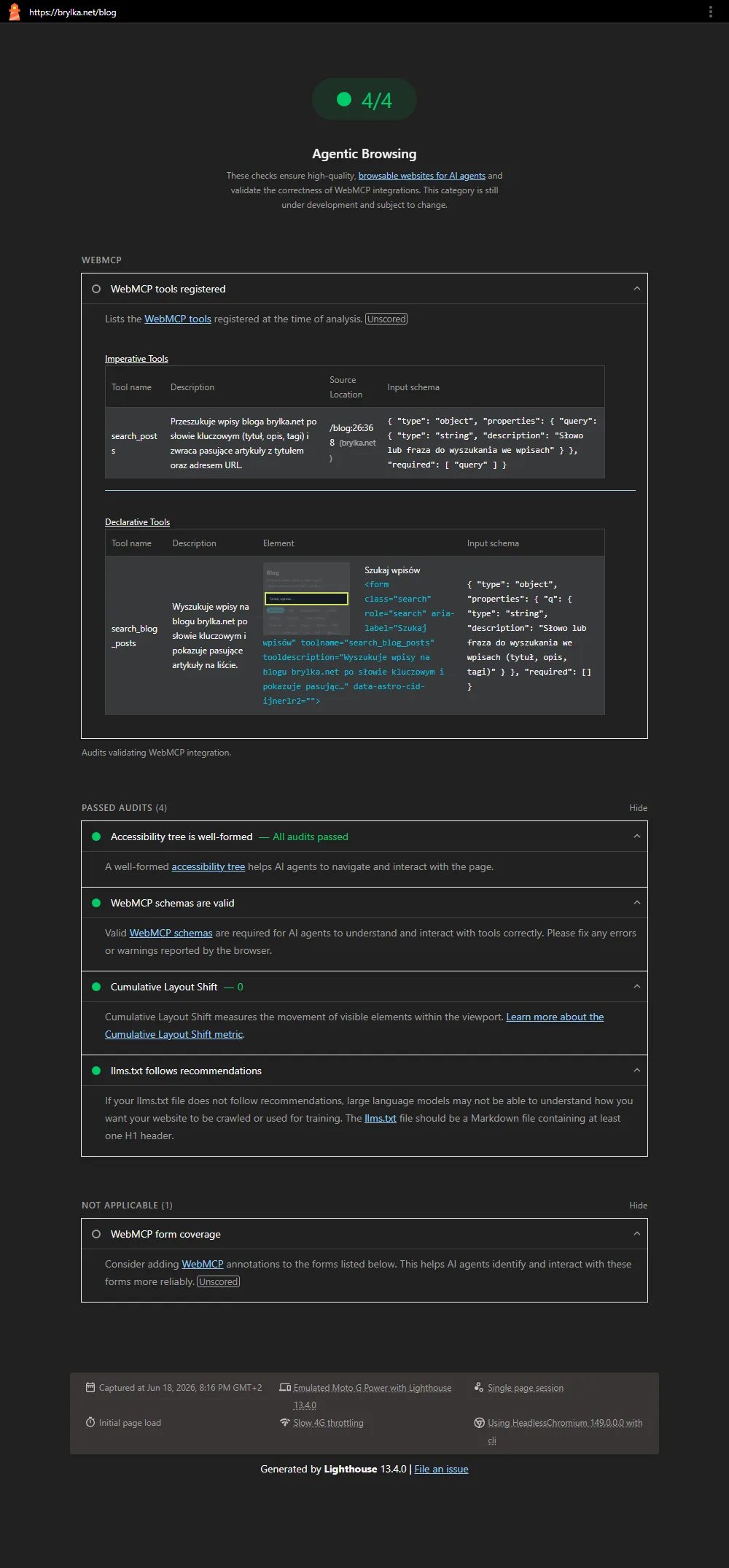
Widać tu sporo: sekcję WebMCP tools registered z oboma narzędziami – imperatywnym search_posts (z lokalizacją w kodzie i schematem) i deklaratywnym search_blog_posts wygenerowanym z naszego formularza – oraz cztery zielone, zaliczone audyty: drzewo dostępności, poprawne schematy WebMCP, CLS 0 i llms.txt.
A teraz szczera analiza, bo „6/6” jest mylące:
- Kategoria jest zawsze zielona (100% tego, co liczy) – nigdy nie zobaczyłem FAIL.
- Liczba się waha: 4/4 ↔ 5/5. Audyt
webmcp-registered-toolsbywa flaky w trybie headless – czasem łapie zarejestrowane narzędzia, czasem nie (kwestia timingu w eksperymentalnej funkcji), więc raz wpada do „zaliczonych”, raz nie. webmcp-form-coverageto audyt informacyjny (Unscored). Gdy formularz jest poprawnie zaadnotowany, nie ma czego zgłaszać → ląduje w „nie dotyczy”. On z natury nie świeci na zielono – to nie usterka, tylko brak uwag.
Wniosek: „6/6” jako sześć zielonych ptaszków po prostu nie istnieje jako stabilny stan. Realny, powtarzalny szczyt to: kategoria 100%, narzędzia i schematy WebMCP wykryte, form-coverage jako informacyjne „nie dotyczy”. I to jest poprawny, dobry wynik – pogoń za mitycznym 6/6 byłaby pogonią za artefaktem niestabilnego, eksperymentalnego audytu.
Czego i tak nie zobaczysz w PageSpeed Insights
Najważniejsze zastrzeżenie praktyczne: w PSI i zwykłym Lighthousie te audyty WebMCP zostaną „nie dotyczy” – bo te narzędzia uruchamiają Chrome bez flagi WebMCP. To bramka środowiskowa, nie kwestia naszego kodu. Żeby zobaczyć WebMCP w akcji:
chrome://flags→ włącz „Experimental Web Platform features” → Relaunch.- Wejdź na
/blog(tam jest formularz; na stronie głównejform-coveragezostanie „nie dotyczy”). - F12 → Console →
navigator.modelContextpowinno zwrócić obiekt. - F12 → zakładka Lighthouse → zaznacz „Przeglądanie agentowe” → Analizuj.
Podsumowanie
Pytanie „czy statyczny blog da radę WebMCP bez backendu” ma jednoznaczną odpowiedź: tak. Statyczny /posts-index.json generowany przy buildzie + filtrowanie po stronie klienta + registerTool (imperatywnie) i adnotacje toolname/tooldescription na formularzu (deklaratywnie) wystarczą, żeby narzędzia i schematy WebMCP były wykrywane – wszystko na edge Cloudflare, zero serwera.
Z pogonią za 6/6 jest jak z wieloma świeżymi metrykami: zanim zaczniesz ją gonić, warto zrozumieć, co dana liczba w ogóle mierzy. Tu okazało się, że pełne „6/6” to mit (jeden audyt jest informacyjny, drugi flaky), a prawdziwą wartością jest realnie zintegrowane WebMCP i – przy okazji – działająca wyszukiwarka wpisów dla zwykłych użytkowników.
Tło samej kategorii rozłożyłem w pierwszym wpisie: Nowa kategoria w Lighthouse: Przeglądanie agentowe. Szczegóły API znajdziesz w dokumentacji Chrome o WebMCP oraz w opisie audytu form-coverage.
